 Scalability.
Scalability.
Scalability.
In order to investigate whether Oracle9i will suffice as database
for storing pipeline results and sourcelists in the TeraByte regime a number
of tests were devised. For these tests a number of objects were designed,
which are a SOURCE and a SOURCE_TABLE object. The idea
is to store the source parameters in a SOURCE object and the collection
of SOURCE objects (which make up a sourcelist) in a SOURCE_TABLE
. The different sourcelist are stored in a table of SOURCE_TABLE
objects.
The objects are defined (in sql) as follows:
-- The SOURCE ObjectSo each source can have 64 parameters, and a nested table is used to store sourcelists in a table.
CREATE TYPE SOURCE AS OBJECT (
RA NUMBER(10,7),
DEC NUMBER(10,7),
FLUX NUMBER,
NAME VARCHAR2(32),
ID NUMBER(32),
TEST NUMBER,
COLOR VARCHAR2(8),
NPAR NUMBER,
IPAR01 NUMBER(12),
IPAR02 NUMBER(12),
IPAR03 NUMBER(12),
.. ..
IPAR27 NUMBER(12),
IPAR28 NUMBER(12),
DPAR01 NUMBER,
DPAR02 NUMBER,
.. ..
DPAR27 NUMBER,
DPAR28 NUMBER
);
-- The SOURCE_TABLE Object
CREATE TYPE SOURCE_TABLE AS TABLE OF SOURCE;
-- The Table for all SOURCE_TABLE Objects
CREATE TABLE SLT (
ID NUMBER(32),
NAME VARCHAR2(32),
ORIGIN VARCHAR2(32),
SOURCES SOURCE_TABLE
)
NESTED TABLE SOURCES STORE AS SLT_SOURCES_TABLE;
100k sources from the USNO catalogue were taken from declination -82
o till -90o to give an adequate number of sources. The
source parameters consist of position, flux and a number of randomly generated
values. Each sourcelist (of 100k sources) in the table takes about 49MB
of disk space which indicates that the Oracle 'storage overhead' is rather
small.
The scalability was tested by ingesting 100k sources at a time and running
a simple query on one of its parameters. The query is setup in such a way
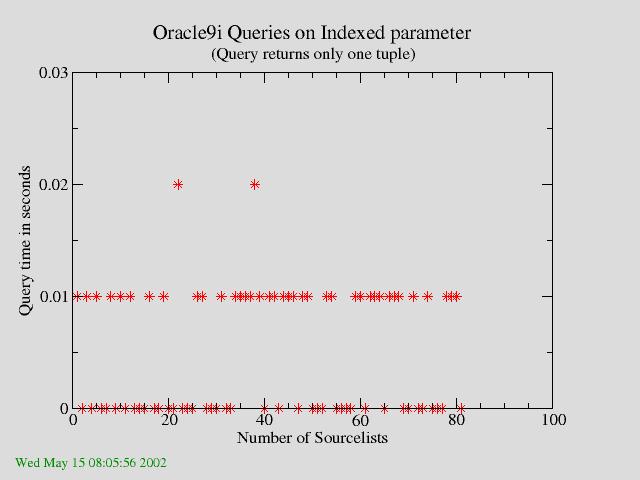
that each query will return only one tuple. The results are shown in figure
1a.
|
| Figure 1a: Query on one Indexed Parameter which returns only 1 tuple. The query time is independant of the number of Sourcelists. |
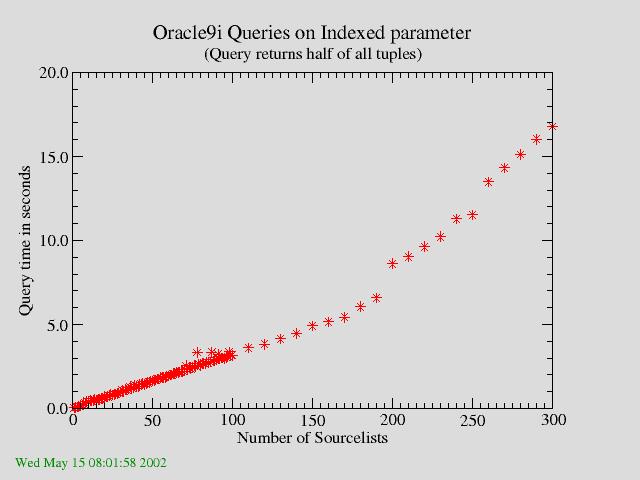
The next test is a Query which returns half of the total number of tuples. The results are shown in figure 1b.
|
| Figure 1b: Query on one Indexed Parameter which returns half of all tuples. The query time is a linear increasing function with the number of Sourcelists. |
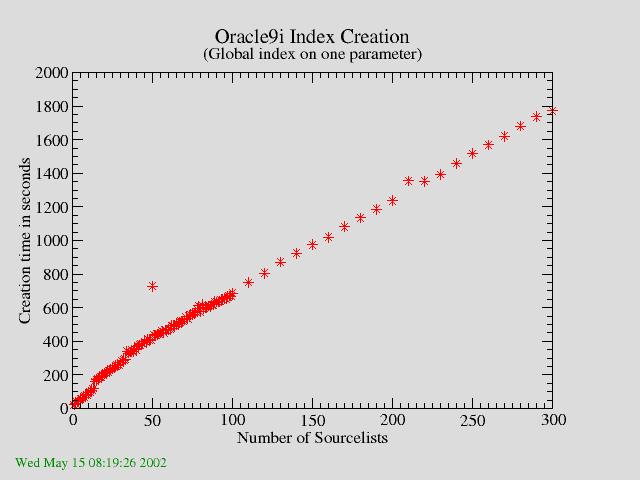
The time needed to create an Index on the parameter on which the above described
queries were run was also measured and the result is shown in figure 2a.
|
| Figure 2a: Time to create an index on one Parameter as function of number of Sourcelists. The time needed increases linearly with database size. |
The extra parameter ID is used to distinguish the different sourcelists.
-- Create a partiononed table
CREATE TABLE PSLT (
ID NUMBER(32),
S SOURCE
)
PARTITION BY RANGE(ID) (
PARTITION PSLT_0 VALUES LESS THAN ( 1 )
);
QUIT
|
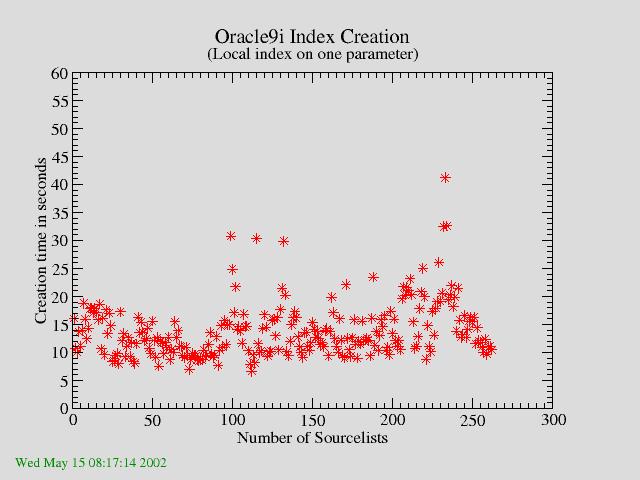
| Figure 2b: Time to create a local index on one Parameter as function of number of Sourcelists. The time needed is independent of the database size. |
The conclusions drawn so far are:
Some things are still under investigation, like: