For this discussion, the following is assumed:
| X | ||||
| X | ||||
| X | ||||
| X | ||||
| X |
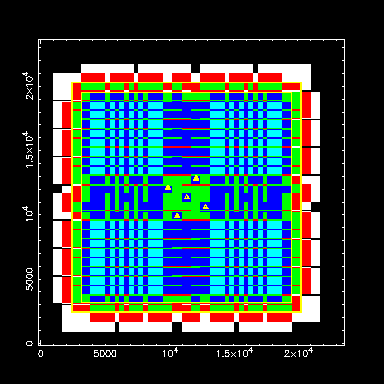 Dither 5: First the exact pattern above, with dither
steps of W=11mm (736 pixels): where black, white and red are areas
covered 0,1 or 2 times, and green, dark blue and light blue 3,4, and 5
times. The centers of the pointings are indicated by triangles. In
this arrangement, the number of pixels with 2 or fewer exposures is
rather low, as are the green (3) areas. This latter point is
important as bad columns, cosmic rays etc will turn green into
red. Statistics of the number of times pixels inside the yellow square
are covered by this dither pattern:
Dither 5: First the exact pattern above, with dither
steps of W=11mm (736 pixels): where black, white and red are areas
covered 0,1 or 2 times, and green, dark blue and light blue 3,4, and 5
times. The centers of the pointings are indicated by triangles. In
this arrangement, the number of pixels with 2 or fewer exposures is
rather low, as are the green (3) areas. This latter point is
important as bad columns, cosmic rays etc will turn green into
red. Statistics of the number of times pixels inside the yellow square
are covered by this dither pattern:
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 69.6 | 69.6 |
| Pixels covered 4 times (Million) | 133.6 | 133.1 |
| Pixels covered 3 times (Million) | 89.3 | 57.7 |
| Pixels covered <3 times (Million) | 26.9 | 8.0 |
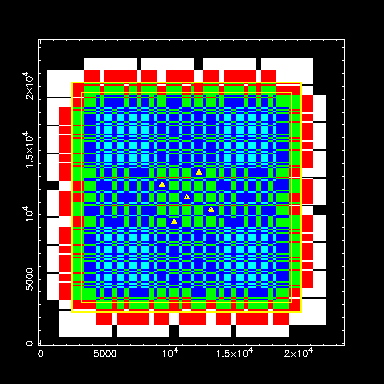 Dither 5a:
Opening
up this dither pattern by a factor 1.3 (W=960 pixels) results in the following
pattern. The red areas have been reduced greatly. The pattern has been
fragmented a bit more, but this looks better than Dither5. The size of
the square area which is covered at least 3 times has only been reduced
very slightly at the corners. Statistics:
Dither 5a:
Opening
up this dither pattern by a factor 1.3 (W=960 pixels) results in the following
pattern. The red areas have been reduced greatly. The pattern has been
fragmented a bit more, but this looks better than Dither5. The size of
the square area which is covered at least 3 times has only been reduced
very slightly at the corners. Statistics:
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 47.7 | 47.7 |
| Pixels covered 4 times (Million) | 137.4 | 137.4 |
| Pixels covered 3 times (Million) | 105.6 | 76.5 |
| Pixels covered <3 times (Million) | 28.7 | 6.8 |
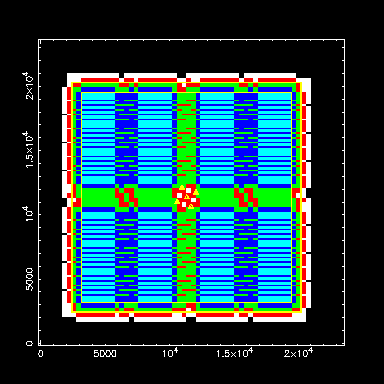 Dither 5b:
Conversely, here's a more compact dither pattern (steps scaled to half of
those of dither5). This arrangement leaves
much larger areas of homogeneous coverage (i.e., the
context map is much less fragmented than in dithers 5 and 5a show above).
However, it must be borne in mind that many bad columns will end up on top
of the large
green areas. A further disadvantage is that the
center of the image contains some pixels which are
covered only once. Statistics:
Dither 5b:
Conversely, here's a more compact dither pattern (steps scaled to half of
those of dither5). This arrangement leaves
much larger areas of homogeneous coverage (i.e., the
context map is much less fragmented than in dithers 5 and 5a show above).
However, it must be borne in mind that many bad columns will end up on top
of the large
green areas. A further disadvantage is that the
center of the image contains some pixels which are
covered only once. Statistics:
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 108.8 | 108.3 |
| Pixels covered 4 times (Million) | 114.2 | 97.7 |
| Pixels covered 3 times (Million) | 78.3 | 52.5 |
| Pixels covered <3 times (Million) | 18.1 | 9.9 |
Given the large fragmentation of these images, I also looked into more compact dither configurations. These will necessarily lead to areas with poor coverage in the center of the resulting image, but the trade-off against homogeneity, dithering software effort, or effects of image distortion, may be worth it. I tried a simple cross-shaped pattern
| X | X | |
| X | ||
| X | X |
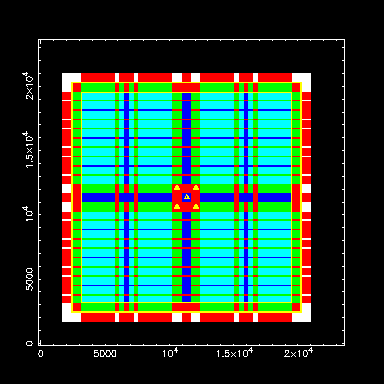 Dither 3:
Dither steps of 11mm, exactly equal to the width of the dead cross. Such
an arrangement causes some regions with only double coverage, but leaves
much larger areas of homogeneous coverage (i.e., the context map is much
less fragmented than in the 5-point dithers show above). However,
there are many more pixels covered 3 or 5 times than 4 times,
leading to sharp jumps in sensitivity. Statistics:
Dither 3:
Dither steps of 11mm, exactly equal to the width of the dead cross. Such
an arrangement causes some regions with only double coverage, but leaves
much larger areas of homogeneous coverage (i.e., the context map is much
less fragmented than in the 5-point dithers show above). However,
there are many more pixels covered 3 or 5 times than 4 times,
leading to sharp jumps in sensitivity. Statistics:
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 142.5 | 141.9 |
| Pixels covered 4 times (Million) | 37.7 | 37.7 |
| Pixels covered 3 times (Million) | 106.2 | 71.1 |
| Pixels covered <3 times (Million) | 33.0 | 17.8 |
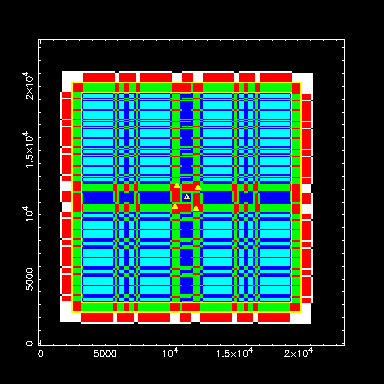 Dither 3a:is a hybrid of the above.
Dither steps of 11mm in x, and 13mm in y, then repeated rotated through
90, 180, 270 degrees. This resembles the 5-point dither pattern above,
but somewhat more compact and at a different angle.
There is little advantage of
this pattern over dither3: red areas are hardly reduced, fragmentation
is greatly increased.
Dither 3a:is a hybrid of the above.
Dither steps of 11mm in x, and 13mm in y, then repeated rotated through
90, 180, 270 degrees. This resembles the 5-point dither pattern above,
but somewhat more compact and at a different angle.
There is little advantage of
this pattern over dither3: red areas are hardly reduced, fragmentation
is greatly increased.
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 104.0 | 104.0 |
| Pixels covered 4 times (Million) | 99.7 | 99.2 |
| Pixels covered 3 times (Million) | 87.7 | 53.0 |
| Pixels covered <3 times (Million) | 28.0 | 12.3 |
| Scheme | 5 | 5a | 5b | 3 | 3a |
| covered 5 times | 69.6 | 47.7 | 108.3 | 141.9 | 104.0 |
| covered 4 times | 133.1 | 137.4 | 97.7 | 37.7 | 99.2 |
| covered 3 times | 57.7 | 76.5 | 52.5 | 71.1 | 53.0 |
| covered <3 times | 8.0 | 6.8 | 9.9 | 17.8 | 12.3 |
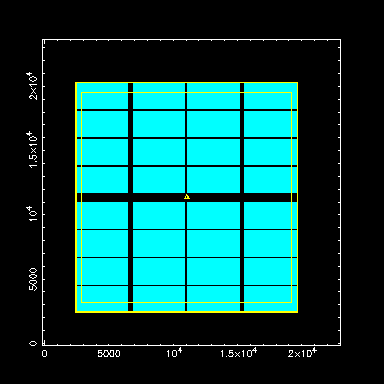
With only a horizontal (perpendicular to the readout-port edges of the CCDs) central gap:
 |
 |
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 78.9 | 78.9 |
| Pixels covered 4 times (Million) | 139.0 | 139.0 |
| Pixels covered 3 times (Million) | 73.4 | 47.5 |
| Pixels covered <3 times (Million) | 17.3 | 3.0 |
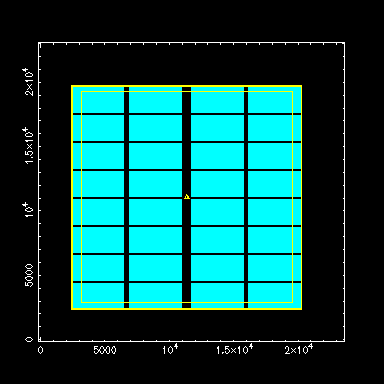
And with only a vertical central gap:
 |
 |
| Outer Square |
Inner Square | |
| Pixels covered 5 times (Million) | 80.5 | 79.2 |
| Pixels covered 4 times (Million) | 153.2 | 148.6 |
| Pixels covered 3 times (Million) | 66.7 | 39.4 |
| Pixels covered <3 times (Million) | 8.1 | 1.2 |
5-point dither schemes with smaller steps result in less fragmented context maps of the final combined image, but at the price of a serious ghost of the central cross. A good compromise appears to be the dither5a scheme.
If the filters can be manufactured in halves, the covered fraction within a square degree can be increased substantially by adopting the same dither5a scheme, with the x- and y-offsets rescaled in proportion to the size of the maximum gap in that direction. In this case aligning the CCD array so that the central gap is parallel to the sides of the CCDs with readout ports appears to give best results.